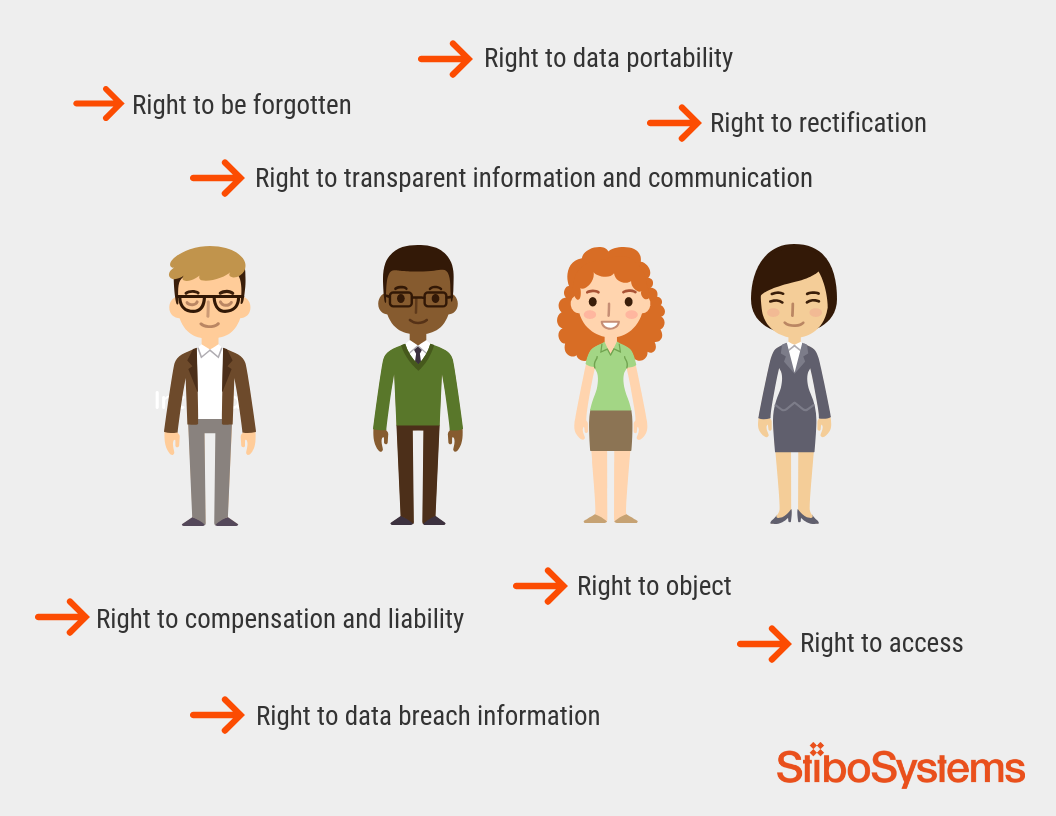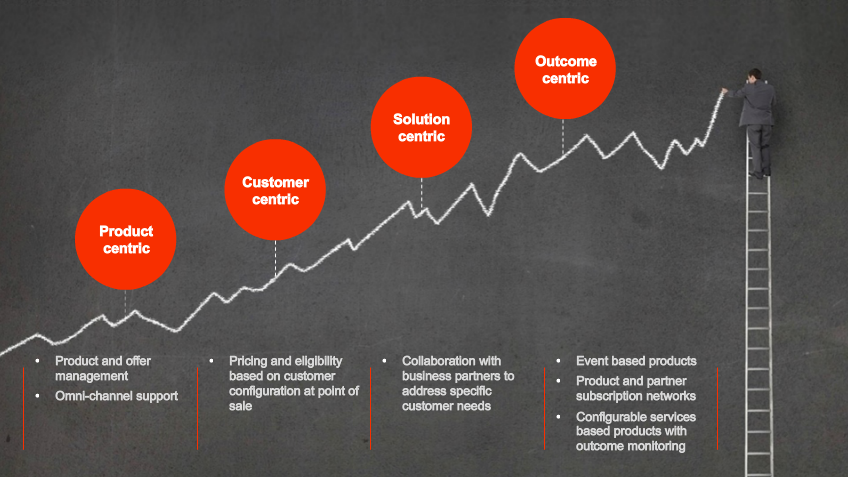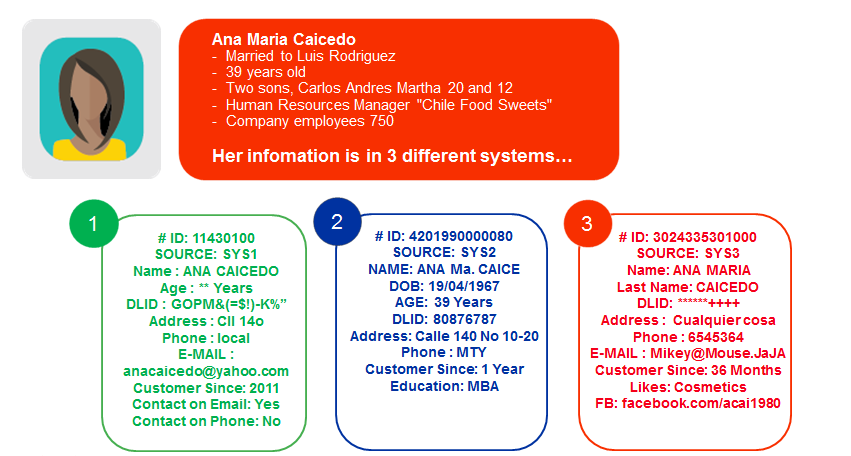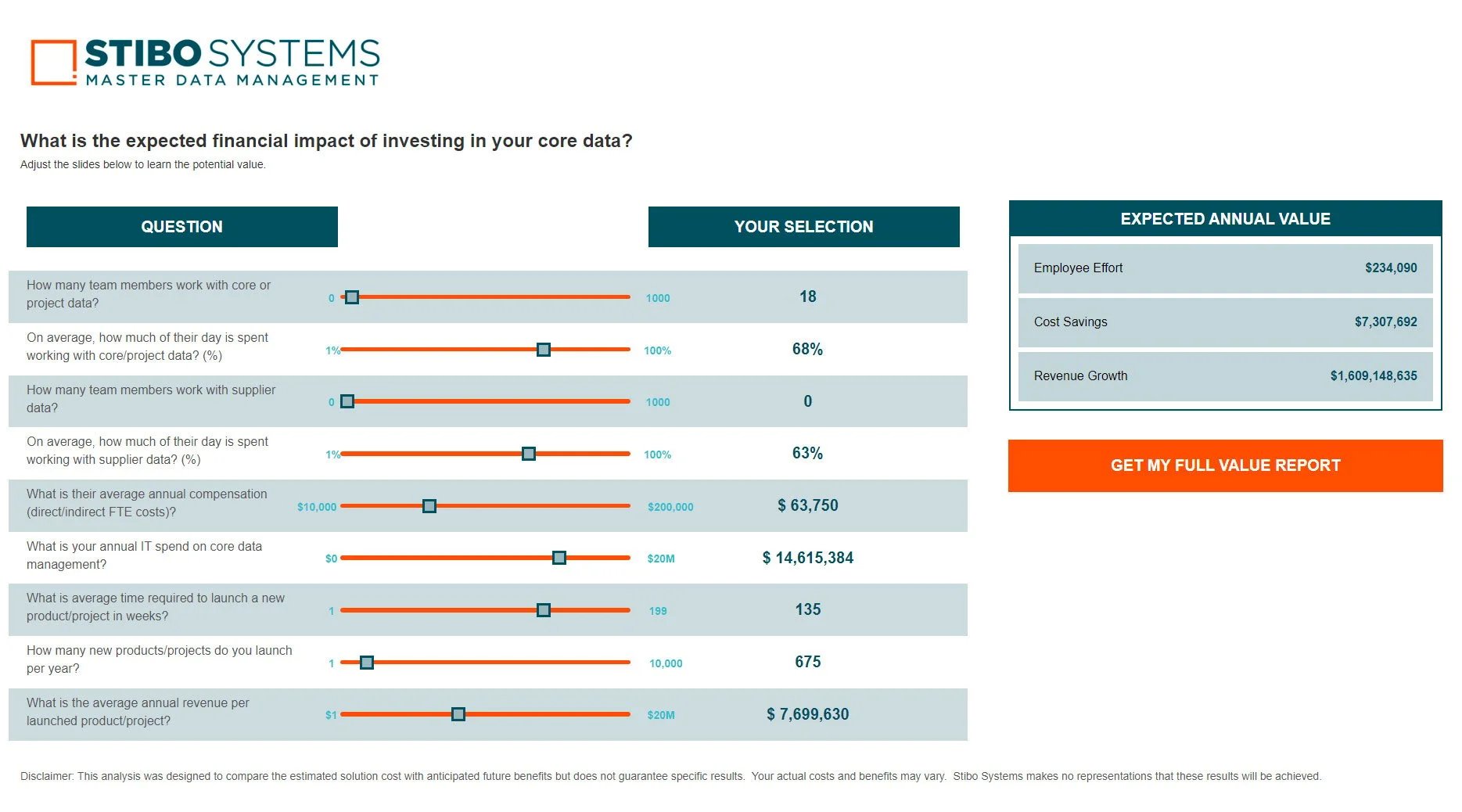






When a chief data officer achieves excellence in master data governance, they’re transformed from someone who spends their time reactively fixing things when data gets messy or breaks a system, to a proactive, all-seeing business enabler...
4/11/24 |
6 minute read